Here is the step by step how to follow this method. Launch a new ec2 instance in your vpc using the same amazon machine image (ami) and in the same availability zone as the impaired instance. The new instance becomes your rescue instance.
Stop your impaired instance. Detach the ebs root volume from your impaired instance. An ec2 instance becomes unreachable if a status check fails.
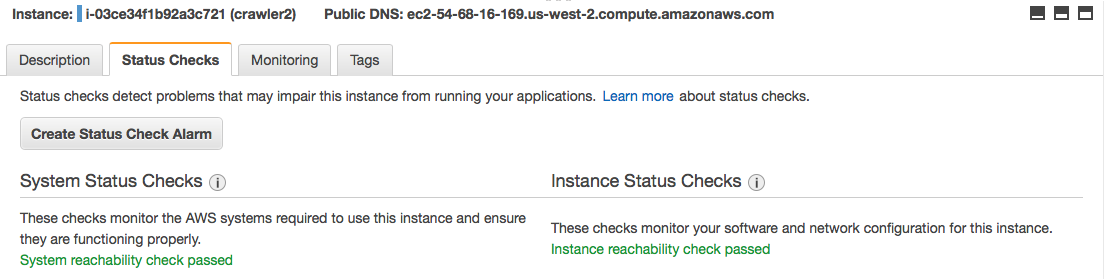
An instance status check failure indicates a problem with the instance, such as: Networking or startup configuration issues. Failure to boot the operating system.
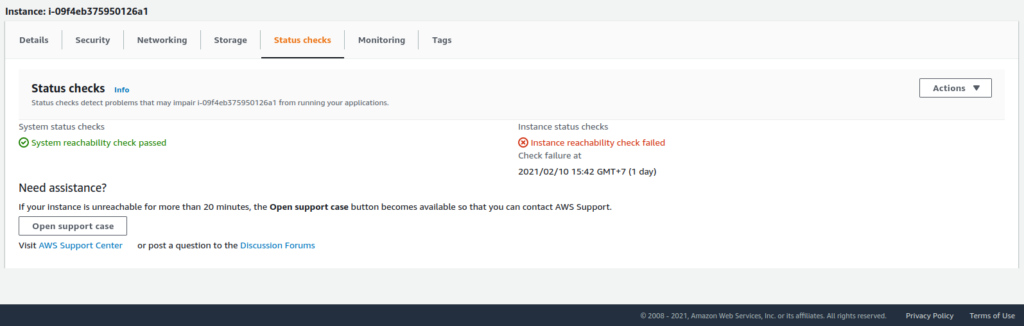
Failure to mount volumes correctly. The status check for the instance says: 'instance reachability check failed'.
Upon checking the security group, inbound traffic for ssh on port 22 is for all ips. The instance status check failure indicates an issue with the reachability of the instance. Some of the following resolutions require an instance stop and start.
Before stopping and starting your instance, be aware of the following: I am using a ubuntu server 18. 04 lts (hvm), ssd volume type ami. I am also unable to connect with the instance using ssh and pinging the public ip also fails.
Normally the memory utilization stays around 80% when i start 3 spring boot servers in it. Instance reachability check means it's an os level issue. If it's booted up successfully, most likely a network issue, where the network stack may have failed to come up.
Check the console logs of the instance. If there isn't much data, you detach the root volume and attach it to another instance to access the logs. We did this and right at the bottom, this is what we saw:
Checking filesystems checking all file systems. I'm using an ec2 t2. micro instance, i can only use it for a while (almost an hour), but then i can't get to the instance: And then it appears instance reachability check failed i don't understand why i can use the instance smoothly for a certain amount of time, and then the network stops working.
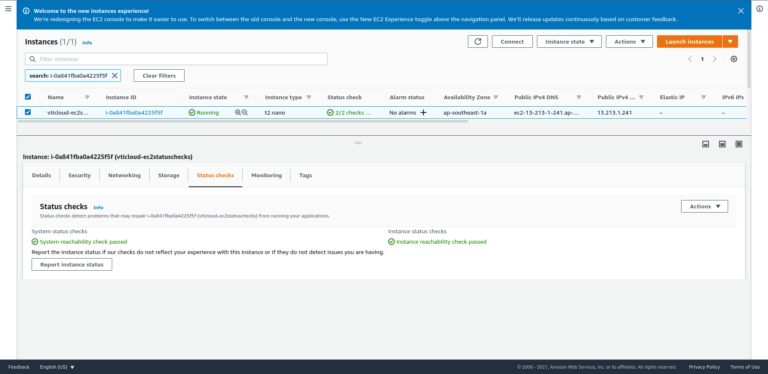
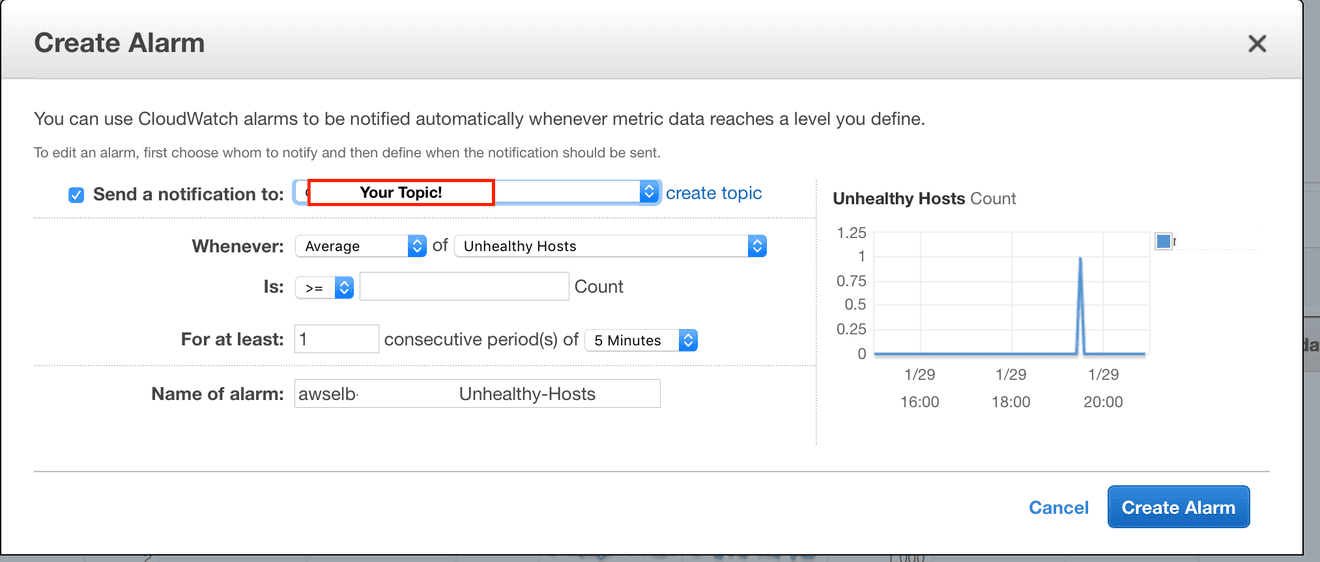
If one or more checks fail, the overall status is impaired. Status checks are built into amazon ec2, so they cannot be disabled or deleted. When a status check fails, the corresponding cloudwatch metric for status checks is incremented.
For more information, see status check metrics. You can use these metrics to create cloudwatch alarms that. If anybody has a similar problem:
The ubuntu 14. 04 is screwed and becomes brain dead if you restart it as it has dhcp problems. Aws support will ask you create a new instance and attach the volume (your initial volume which does not boot) and try to increase the timeout (it would be 300 by default). Aws ec2 status check says instance reachability check failed with kernel panichelpful?
Please support me on patreon: If any of the status checks fail, you might see a status such as impaired. You can also check a particular ec2 instance by adding the instanceid to the previous command:
Or apply a filter to these values by the following command: I experienced an instance reachability issue a few weeks ago. I then realized my ansible hardening script modified rhel os grub. conf.
I had to revert it with the help of aws support. I also take daily backups. Try ec2 serial console or reach out to support or restore from backup.
Jaccopk 7 months ago. I can't log onto my ec2 instance, and it says instance reachability check failed. It's been over 24 hours and nothing.
I have code and data on the instance that i didn't back up, and which i. Create an instance recovery alarm. For more information, see create alarms that stop, terminate, reboot, or recover an instance.
If you changed the instance type to an instance built on the nitro system, status checks fail if you migrated from an instance that does not have the required ena and nvme drivers. for more information, see compatibility for changing the instance type. Detach the secondary volume from the temporary instance and attach it back to the original instance as root volume(/dev/xvda) start the original instance and check if you are able to login to the instance. In case you still face any issues, please feel free to comment.
My cloud watch report [1] log file of instance reachability check failed. My ec2 is not reachable anymore. I am running a t3. micro ubunto instance.